
GraphRAG vs Vector RAG: When Relationships Beat Chunks
Ask your RAG system “what’s our refund window?” and it nails it. The right chunk is sitting in the policy doc, semantically close to the question, and vector search hands it over in 40 milliseconds. Beautiful.
Now ask “which engineers own the services that feed the dashboard finance uses for the churn number?” and watch it fall apart.
That second question doesn’t live in one chunk. The answer is spread across five documents connected by relationships — owns, feeds, uses — and similarity search has no concept of a relationship. It fetches three passages that each mention “churn” or “dashboard,” shrugs, and lets the model guess. This is the wall every team hits eventually, and it’s exactly where the GraphRAG vs vector RAG question stops being academic.
Here’s the honest comparison: what each one actually does, where each wins, what the research shows when you strip out the hype, and how to decide without burning a quarter on the wrong architecture.
Table of Contents
- TL;DR: the comparison in one table
- Vector RAG: what it is and where it wins
- GraphRAG: what it is and where it wins
- Head-to-head: multi-hop reasoning
- Head-to-head: cost, latency, and maintenance
- What the research actually shows
- Which should you choose?
- FAQ
TL;DR: the comparison in one table
| Dimension | Vector RAG | GraphRAG |
|---|---|---|
| Retrieves by | Semantic similarity (embeddings) | Entity-relationship traversal |
| Best at | Single-fact lookups, semantic search | Multi-hop, relationship, and summarization queries |
| Setup cost | Low — embed and index | High — entity extraction + graph build |
| Query latency | Low and predictable | Scales with traversal depth |
| Maintenance | Re-embed changed docs | Keep the graph in sync as data changes |
| Explainability | A similarity score | A traceable path through entities |
| Global “summarize the whole corpus” queries | Expensive, often shallow | Cheaper via precomputed community summaries |
Neither column is the winner. The right answer is almost always “both, for different queries” — but you can’t make that call without understanding what each is doing under the hood.
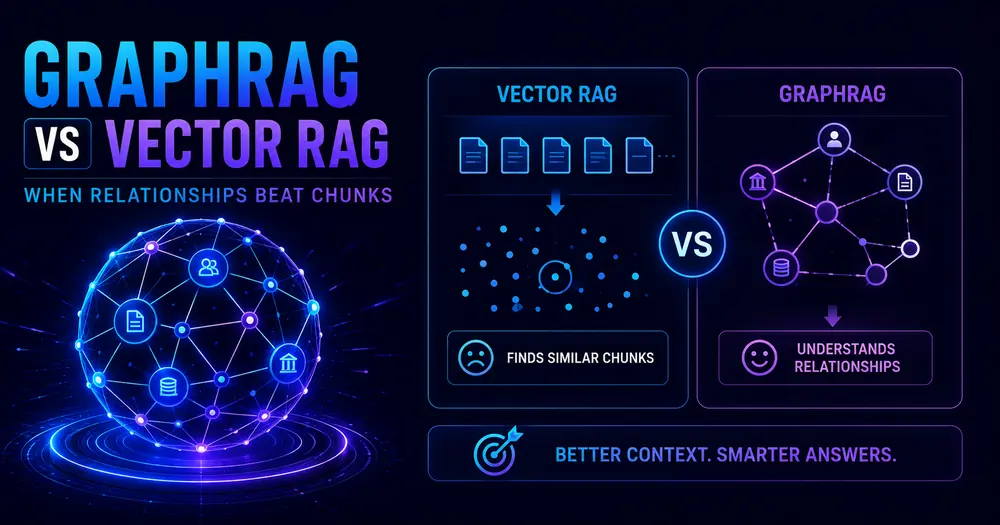
Vector RAG: what it is and where it wins
Vector RAG is the default, and for good reason. You split documents into chunks, run each through an embedding model, and store the resulting vectors in a database like Pinecone, Weaviate, Milvus, or pgvector. At query time you embed the question, find the nearest chunks by cosine similarity, and stuff them into the prompt.
It’s fast, cheap, and astonishingly good at one thing: finding text that means the same as your query, even when the words differ. Ask about “time off policy” and it’ll surface the section titled “annual leave” without anyone wiring up a synonym. For FAQ bots, documentation search, and “find me passages about X,” it’s hard to beat on effort-to-value.
The catch is that its entire quality ceiling is set by your chunking. Slice documents badly and retrieval returns fragments that cut off mid-thought, or splits one answer across two chunks so neither scores as relevant. If your vector setup “can’t find” something that’s obviously in the corpus, the bug is almost always upstream in how you sliced it — which is its own chunking deep dive.
The harder limit is structural: vector search has no model of how facts connect. Every chunk is an island. That’s fine until the question requires hopping between islands.
GraphRAG: what it is and where it wins
GraphRAG attacks the problem from the other end. Instead of embedding text and hoping similarity captures meaning, it uses an LLM to read your corpus and extract a knowledge graph — entities (people, services, policies, metrics) as nodes, and the relationships between them as edges. Retrieval becomes traversal: the system finds the entities in your question, then walks the graph to assemble connected context.
For that finance question earlier, a graph answers it directly. It walks dashboard → metric → calculation → source table → pipeline → owner, and each hop adds a fact the model needs. The traversal is the reasoning. Vector search can’t replicate that, because it was never storing the connections in the first place.
Microsoft’s GraphRAG project adds a second trick on top: community detection. It clusters related entities into “communities” and precomputes a summary for each one. That’s what lets it answer corpus-wide questions — “what are the main themes across these 500 reports?” — that vector RAG can only approximate by retrieving a handful of chunks and praying they’re representative.
The cost is real, though. You’re running an extraction pipeline over your whole corpus, standing up a graph store (Neo4j and friends), and keeping that graph in sync every time the underlying data changes. That’s engineering time vector RAG simply doesn’t ask for.
Head-to-head: multi-hop reasoning
This is the cleanest dividing line between the two.
A single-hop query — “what does the SLA say about uptime?” — is a lookup. Vector RAG owns it. The fact is in one place; similarity finds it.
A multi-hop query needs you to connect intermediate facts that no single chunk contains. Here’s the contrast in code. With vector RAG you retrieve by similarity and hand the model a bag of chunks:
# Vector RAG: similarity gives you candidates, not connections
hits = vector_db.query(
embedding=embed("who owns the services behind the churn dashboard?"),
top_k=5,
)
context = "\n\n".join(h.text for h in hits)
# The model now has 5 loosely related chunks and must infer the links itself.Code language: Python (python)With a graph, the connection is the query. You match the starting entity and traverse the actual relationships:
// GraphRAG: the relationships ARE the retrieval MATCH (d:Dashboard {name: “Churn”})-[:USES]->(m:Metric) MATCH (m)<-[:FEEDS]-(s:Service)-[:OWNED_BY]->(e:Engineer) RETURN e.name, s.name, m.nameThe graph returns exactly the chain of facts that answers the question. The vector query returns five things that are about the topic and offloads the hard part — figuring out how they relate — onto the model, which is where hallucinated connections creep in.
💡 Tip — the multi-hop wall is a good trigger for a hybrid design. Route lookup-style questions to vector search and relationship-style questions to the graph. You don’t have to pick one for the whole app.
Head-to-head: cost, latency, and maintenance
On day-one cost, vector RAG wins easily. Embed, index, ship. GraphRAG makes you pay up front: an LLM extraction pass over the corpus, a graph database to run, and a sync process so the graph doesn’t drift from reality. Skip that sync and your graph quietly rots — answers stay confident while the relationships go stale.
Latency tells a similar story for simple queries. A top-k vector lookup is fast and predictable; graph traversal cost grows with how many hops you take and how dense the graph is.
But there’s a genuinely counterintuitive twist, and it’s the part most comparisons miss. For global queries — the “summarize everything” kind — GraphRAG can be the cheaper option at inference time, because the community summaries are computed once and reused. Microsoft reported that this precomputation slashed the token count for corpus-level summarization dramatically versus repeatedly feeding raw chunks to the model. So the cost story isn’t “graph is always pricier.” It’s “graph is pricier to build, sometimes cheaper to query” — which matters once you’re watching the inference bill climb on a high-traffic system.
There’s also a 2026 wrinkle worth knowing: Microsoft’s LazyGraphRAG variant defers most of the expensive indexing, narrowing the setup-cost gap that historically made teams skip graphs entirely. The economics that ruled GraphRAG out two years ago are shifting.
What the research actually shows
Strip the marketing and the picture is consistent but narrower than the headlines suggest.
Microsoft’s “From Local to Global” research evaluated GraphRAG against a vector-RAG baseline using an LLM as a judge, scoring pairwise winners on comprehensiveness (does the answer cover the whole question) and diversity (does it bring multiple relevant angles). GraphRAG won consistently on both, especially on broad, sensemaking questions over a full corpus. The same work documented the token-cost advantage on global queries from community summaries. Independent benchmarks since have echoed the direction — graph grounding helps most on multi-hop and schema-heavy questions — though the exact percentages vary enough between studies that I’d treat any single number with caution.
On the adoption side, the analysts have caught up. Gartner’s 2025 guidance explicitly tells teams to evaluate and combine RAG techniques — vector search, graph, and chunking — rather than standardizing on one, and its 2025 Hype Cycle moved knowledge graphs onto the “Slope of Enlightenment,” the stage that signals a technology maturing into mainstream use. Read together, the message is the same one the engineering data points at: this isn’t a winner-take-all fight.
⚠️ Note: Benchmark numbers for GraphRAG swing widely by dataset and query type. The reliable finding is directional — graphs help most on relationship-heavy and corpus-wide questions — not any specific accuracy figure. Treat single-number claims, including the ones in vendor blog posts, as marketing until you’ve reproduced them on your own data.
Which should you choose?
Start with vector RAG. Almost always. It’s cheaper, faster to ship, and handles the majority of real queries — lookups and semantic search — better than its reputation among graph enthusiasts suggests. If your corpus is mostly unstructured text and your users mostly ask “find me information about X,” you may never need more.
Add a graph when you hit the relationship wall — and you’ll know when you do, because users start asking questions your retrieval can’t answer no matter how good your embeddings get. Multi-hop questions. “How is this connected to that?” Corpus-wide summaries. Anything where the answer is in the connections between facts, not the facts themselves. The same goes for cases where you need to explain an answer: a graph hands you a traceable path, while a vector score is a black box.
The mature 2026 pattern is hybrid. Vector for the bulk of traffic, graph for the relationship-heavy minority, and a router deciding which gets which. It costs more to build than either alone, but it stops you forcing every query through a tool that was never designed for it — the same “more isn’t automatically better, the right tool is” lesson that runs through context collapse and most of the other AI concepts worth knowing in 2026.
Pick the architecture that matches your queries, not the one that demos well.
FAQ
What is the difference between GraphRAG and vector RAG?
Vector RAG retrieves text by semantic similarity: it embeds your chunks and your query, then returns the closest matches. GraphRAG retrieves by traversing a knowledge graph of entities and their relationships, so it can follow explicit connections between facts. Vector RAG is best at finding passages about a topic; GraphRAG is best at answering questions that require linking several facts together.
Is GraphRAG better than vector RAG?
Not universally. GraphRAG wins on multi-hop reasoning, relationship queries, corpus-wide summarization, and explainability. Vector RAG wins on setup cost, query speed, and straightforward semantic lookups, which are the bulk of most workloads. Most production systems in 2026 use both and route each query to the method that fits it.
Is GraphRAG more expensive than vector RAG?
It’s more expensive to build and maintain — you run an entity-extraction pipeline and keep a graph in sync. But for large “summarize the whole corpus” queries it can be cheaper at inference time, because community summaries are precomputed once and reused. Newer variants like LazyGraphRAG also reduce the upfront indexing cost.
Do I need a graph database to use GraphRAG?
Usually yes — a graph store such as Neo4j is the natural home for the entities and relationships. Microsoft’s open-source GraphRAG library handles the extraction and community-summary pipeline and can be paired with various backends. You can prototype on smaller setups, but production graphs need a real graph store.
When should I switch from vector RAG to GraphRAG?
When your users consistently ask questions that span multiple connected facts and vector retrieval keeps returning related-but-incomplete chunks. That’s the signal the answer lives in the relationships, not in any single passage. Until then, vector RAG with good chunking is the lower-cost, lower-effort choice.
📚 READ NEXT
→ Chunking Is Quietly Breaking Your RAG System — diagnose and fix bad retrieval
→ KV Cache: Why Long Context Isn’t Free — the memory cost behind every long prompt
