
Chunking Is Quietly Breaking Your RAG System
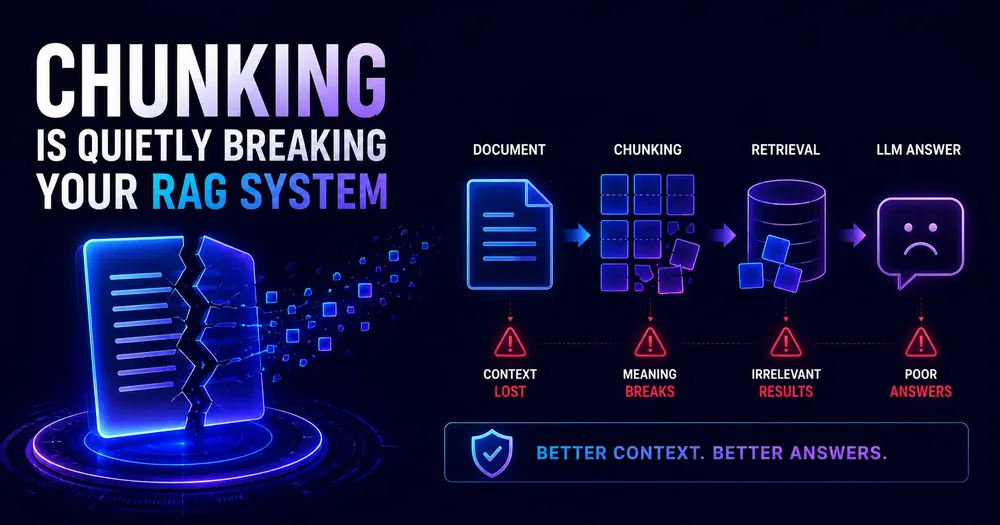
You can see the answer. It’s right there in the PDF — page 14, second paragraph, exactly what the user asked. But your RAG system swears it doesn’t exist. It returns three vaguely related passages, the model shrugs out a “I don’t have information on that,” and you spend the afternoon convinced your embeddings are broken or your vector database is misconfigured.
They’re probably fine. The bug is upstream, in the least glamorous part of the whole pipeline: how you cut the documents into pieces.
Chunking is the step everyone configures once, copies from a tutorial, and never looks at again. And it’s the single most common reason a retrieval system “can’t find” something that is obviously sitting in the corpus. Get your RAG chunking strategy wrong and no amount of fancier embeddings or a bigger model will save you — you’re searching over fragments that were broken in the wrong place.
Here’s how to tell if chunking is your problem, and four fixes in rough order of effort.
Table of Contents
- Why bad chunking quietly wrecks retrieval
- A 60-second diagnostic
- Fix 1 — Stop using fixed-size chunking
- Fix 2 — Right-size your chunks (and rethink overlap)
- Fix 3 — Give each chunk its context before embedding
- Fix 4 — Semantic and late chunking
- How to know it actually worked
- Preventing chunking regressions
- FAQ
Why bad chunking quietly wrecks retrieval
Retrieval works by similarity. You embed each chunk into a vector, embed the query, and return the chunks whose vectors sit closest to the query’s. The whole thing rests on one assumption: that each chunk is a coherent, self-contained unit of meaning.
Break that assumption and everything downstream suffers. Split a document every 1,000 characters with no regard for structure and you get chunks that start mid-sentence, end mid-table, or jam the tail of one section onto the head of the next. Now the embedding is a blurry average of two unrelated ideas, and it sits in vector space near nothing in particular — including the query that needed it.
The second failure is subtler: lost references. A chunk that reads “It raised the limit to 50GB in the March release” is useless on its own. What raised it? Which product? The antecedent was three paragraphs up, in a different chunk, and the embedding has no idea what “it” refers to. The fact is in your corpus. It’s just been severed from the words that make it findable.
This is the quiet part. Nothing errors. No exception, no log line. Retrieval just gets a little worse, invisibly, on exactly the queries that matter most.
A 60-second diagnostic
Pull up the actual chunks your retriever returns for a few failing queries — not the final answer, the raw retrieved chunks. Then look for these tells:
- Chunks start or end mid-sentence. Classic fixed-size splitting. The boundaries were placed by a character counter, not by meaning.
- The correct passage exists but never makes the top-k. The information is in the corpus but its chunk embeds poorly — usually a boundary or context problem.
- One chunk covers two unrelated topics. You’re splitting on the wrong boundaries, averaging two ideas into one muddy vector.
- Chunks lean on dangling references — “it”, “this feature”, “the company” — with no antecedent inside the chunk. That’s lost long-distance context.
- Quality drops specifically on long source documents. Short docs are fine; long ones fall apart. A strong signal that context is being severed at chunk boundaries.
If you nodded at two or more of these, chunking is your bug. Keep reading. If your chunks look clean and retrieval still misses, the problem may be that your questions need relationships between facts, not better passages — that’s a different tool entirely, covered in GraphRAG vs vector RAG.
Fix 1 — Stop using fixed-size chunking
Fixed-size chunking is what you get from the simplest possible tutorial. It splits on a raw character or token count and ignores the document completely:
# Fixed-size: blind to structure. Splits mid-sentence, mid-table, mid-thought.
chunks = [text[i : i + 1000] for i in range(0, len(text), 1000)]Code language: Python (python)It’s fast and it’s a disaster for anything with structure. The fix that solves 80% of chunking pain — and the one to reach for first — is recursive splitting. It tries to break on the most meaningful boundary available (paragraph), and only falls back to finer ones (line, sentence, word) when a piece is still too big:
# Recursive: split on natural boundaries first, fall back only when forced.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # target size; tune to your embedding model
chunk_overlap=64, # ~12%; see Fix 2 on whether you even need this
separators=["\n\n", "\n", ". ", " ", ""], # paragraph → line → sentence → word
)
chunks = splitter.split_text(text)Code language: Python (python)The separators list is the whole trick: it prefers to cut between paragraphs, and resorts to splitting a sentence only when there’s no larger boundary that fits. For most prose, this alone turns muddy, mid-sentence chunks into clean, self-contained ones — and recursive 512-token splitting consistently ranks at or near the top in 2026 retrieval benchmarks. Start here before anything fancier.
Fix 2 — Right-size your chunks (and rethink overlap)
Chunk size is a precision-versus-context tradeoff, not a “bigger is better” dial. Small chunks (around 256 tokens) embed tightly and nail fine-grained, fact-lookup queries, but lose surrounding context. Large chunks (1,000+) carry more context but dilute the embedding, so the specific fact you need gets averaged out. A 512-token target is the defensible default for mixed prose; 512–1,024 is a sane range to test within.
Now the part most guides get wrong. The standard advice is to add 10–20% overlap between chunks so a thought that straddles a boundary isn’t lost. Reasonable on its face — but a January 2026 systematic analysis found that overlap added no measurable retrieval benefit in its tested setup, while quietly inflating index size and embedding cost. That doesn’t make overlap useless; it makes it a tunable, not a commandment.
⚠️ Note: Don’t treat 10–20% overlap as a law of nature. It helps in boundary-sensitive corpora (dense legal or technical text where a single sentence spans a split), and does little in well-structured docs while costing you tokens. Measure it on your data before paying for it everywhere.
This is the same trap that shows up across the stack — reflexively adding “more” (more overlap, more retrieved chunks, more context) on the assumption it must help, when it often just adds cost and noise. The context-collapse problem is the same mistake one layer up.
Fix 3 — Give each chunk its context before embedding
Recursive splitting fixes where you cut. It doesn’t fix the dangling-reference problem from earlier — a clean chunk can still be meaningless in isolation if its subject lives elsewhere in the document.
The highest-leverage upgrade here is contextual retrieval, the technique Anthropic published in 2024. The idea is almost embarrassingly simple: before you embed a chunk, prepend a short, LLM-generated blurb that situates it within its parent document. The chunk goes from “It raised the limit to 50GB in the March release” to “This section is about the Pro plan’s storage; it raised the limit to 50GB in the March release” — and now it embeds near the queries that need it.
# Prepend a document-aware blurb to each chunk BEFORE embedding it.
def contextualize(chunk: str, full_doc: str) -> str:
context = llm(
f"<document>\n{full_doc}\n</document>\n"
f"<chunk>\n{chunk}\n</chunk>\n"
"In 1-2 sentences, situate this chunk within the document so it "
"stands on its own. Output only that context, nothing else."
)
return f"{context}\n\n{chunk}"
# Embed the contextualized version, store the original for the prompt.
embedding = embed(contextualize(chunk, full_doc))Code language: Python (python)Anthropic’s reported numbers are the reason this is worth the trouble: contextual embeddings alone cut top-20 retrieval failures by roughly 35%, combining them with keyword (BM25) search pushed that to about 49%, and adding a reranking step reached around 67%. The obvious objection is cost — you’re making an LLM call per chunk — but prompt caching on the full document keeps it cheap at scale, since the bulky shared context is only paid for once.
Fix 4 — Semantic and late chunking
Two more advanced strategies, both genuinely useful and both easy to over-adopt.
Semantic chunking places boundaries where the meaning shifts, by comparing the embeddings of adjacent sentences and cutting where similarity drops. It produces beautifully coherent chunks. It’s also roughly an order of magnitude slower than token-based splitting, because you embed every sentence just to decide where to cut. Worth it for high-value, accuracy-critical corpora; overkill for a FAQ bot.
Late chunking, introduced by Jina AI, inverts the usual order. Instead of splitting then embedding, it runs the whole document (or a large span) through a long-context embedding model first, then pools the token-level output into per-chunk vectors at the end. Because every chunk vector is computed with the full document in view, references like “it” and “the city” inherit their context automatically. It’s not a replacement for recursive or semantic splitting — it’s a layer on top of whatever boundaries you choose, available as a late_chunking=True flag in Jina’s embeddings API.
💡 Tip — don’t jump straight to semantic or late chunking. The order that pays off for most teams is: recursive splitting → right-sized chunks → contextual retrieval → then semantic or late chunking only if your retrieval metrics still justify the added cost and latency.
How to know it actually worked
Here’s the discipline most teams skip: chunking changes are guesses until you measure them. “It feels better” is not a result.
Build a small evaluation set — a few dozen real queries, each paired with the chunk (or document) that should be retrieved. Then track recall@k: the fraction of queries whose correct chunk lands in the top k results. Its inverse, the retrieval failure rate, is the number Anthropic reports against, and it’s the one to watch when you change anything about chunking.
# recall@k: fraction of queries whose gold chunk appears in the top k results.
def recall_at_k(queries, k=20):
hits = sum(
gold_chunk_id(q) in [c.id for c in retrieve(q, k)]
for q in queries
)
return hits / len(queries)Code language: Python (python)Run it before and after every chunking change. If recall@20 doesn’t move, you just spent effort for nothing — revert and try the next lever. This is the same measure-don’t-guess habit that underpins building evals for any AI feature; retrieval quality is just one more thing you test instead of vibe-checking.
Preventing chunking regressions
Once it’s working, keep it working. Re-run your recall@k eval on every change to the ingestion pipeline — a new document type, a tweaked splitter config, a swapped embedding model can all silently shift your boundaries. Version your chunking config alongside your code so a retrieval regression can be traced to the change that caused it. And re-examine the strategy whenever your corpus changes shape: the splitter that’s perfect for clean Markdown docs will mangle scanned PDFs or chat transcripts.
Chunking isn’t a set-and-forget decision. It’s a parameter of your system that deserves the same monitoring as latency or error rate — because when it drifts, nothing tells you. The answers just quietly get worse. It’s one of nine concepts worth keeping sharp in the 2026 AI terms guide for developers, and it’s the one hiding in plain sight.
FAQ
What is the best chunking strategy for RAG?
For most use cases, recursive character splitting at around 512 tokens is the best default — it respects document structure by splitting on paragraphs first and only breaking sentences when forced. Move to semantic, contextual, or late chunking only when a measured retrieval metric shows the default isn’t good enough. There’s no universal best; the right strategy depends on your documents and query types.
What chunk size should I use for RAG?
A 512-token target is a strong starting point, with 512–1,024 a reasonable range to test. Smaller chunks favor precise fact lookups; larger chunks preserve more context but dilute the embedding. The correct size is the one that maximizes recall@k on your own evaluation set, so test rather than guess.
Do I need overlap between chunks?
Not always. The common 10–20% overlap rule helps in boundary-sensitive corpora where a single idea straddles a split, but a 2026 analysis found it added no measurable benefit in some setups while increasing index size and cost. Treat overlap as a parameter to test on your data, not a mandatory default.
Why does my RAG system miss information that’s clearly in the documents?
The most common cause is chunking. Fixed-size splitting can cut the relevant passage mid-thought, or sever it from the context that makes it findable, so its embedding sits far from the query in vector space. Switching to recursive splitting and adding contextual retrieval fixes the majority of these “it’s right there but won’t retrieve” failures.
What is contextual retrieval?
Contextual retrieval, from Anthropic, prepends a short LLM-generated summary to each chunk before embedding, situating it within its source document. Anthropic reported it cut top-20 retrieval failures by roughly 35% on its own, around 49% combined with keyword search, and about 67% with reranking added. Prompt caching keeps the per-chunk LLM cost low at scale.
